

发布日期:2024-10-30 23:05 点击次数:80

导读:跟着 B 站业务的快速发展,大数据的限度和复杂度也突飞大进。为应酬这一挑战,B 站一站式大数据集群管制平台(BMR),在千呼万唤中滋长而生。BMR 平台包含集群管制、元仓建设、智能运维等中枢模块,这些功能很好的贯串了业务场景的需求,显赫涵养了变更成果助记词转换私钥ledger助记词,保险了系统安全变更,优化了运维进程。本次共享将凝视先容 BMR 平台的各个模块功能超过在实践应用中取得的成效。
01 配景先容
1. BMR 的出生
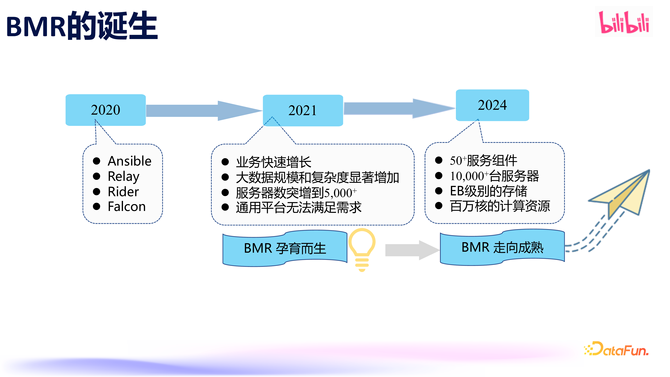
B 站于 2021 年推出了一站式大数据集群管制平台(BMR)。那时业务发展迅猛,随之而来的是大数据限度和业务复杂度的连接增多,传统的 CI/CD 平台照旧无法傲气快速增长的需求。为了治理这一问题,咱们开导了我方的大数据基础组件管制系统。经过三年的发展,面前 BMR 管制着越过 50 个处事组件、领有上万台机器、EB 级别的存储和百万核的诡计资源。
2. BMR 发展阶段

领先的 BMR 上演着救火队员的变装,治理进攻的问题和需求。跟着发展,BMR 变得像战役机一样,边加油边战役,保险咱们的大数据处事组件概况抓续踏实运行。BMR 的发展主要履历了四个阶段。
第一阶段,起程点聚焦于环境圭臬化、处事设置的圭臬化,治理豪爽成长过程中非标坐褥留住的债务,举例环境设置参差词语、日记目次、安设包管制不法式等问题;其次,BMR 的另一职责等于傲气中枢组件的快速迭代发布需求。
第二阶段,启动建设元仓、千里淀业务元、故障等数据,买通处事间的数据互通;同期请示组件的覆盖面,由中枢组件缓缓膨大至更多处事组件,逐渐终明晰全面覆盖;在此过程中,也伴跟着一些机房挪动、在线离线混部、潮汐混部等场景化的建设
第三阶段,为了顺应通盘公司的发展,拥抱云原生,BMR 膨大了容器化管制的才智,傲气 Spark、Flink 等处事逐渐向 K8S 挪动的需求;另外,元仓数据也启动逐渐被应用,如容量管制和 SLO,任务会诊责任等,基于元仓数据,咱们还终明晰一些智能运维的才智,旨在涵养成果,摆脱双手。
现阶段,也等于第四阶段,智能运维平台进一步升级,在之前的故障自愈的基础上,又开导了故障预测的功能,比如热门机器、磁盘性能下落等;另外,还衔尾大模子开导了智能问答系统,使运维成果得到了大幅涵养;针对不同的需求,咱们使用定制的 Manager 来管制,使处事更踏实更详尽化。
3. BMR 产物蓝图
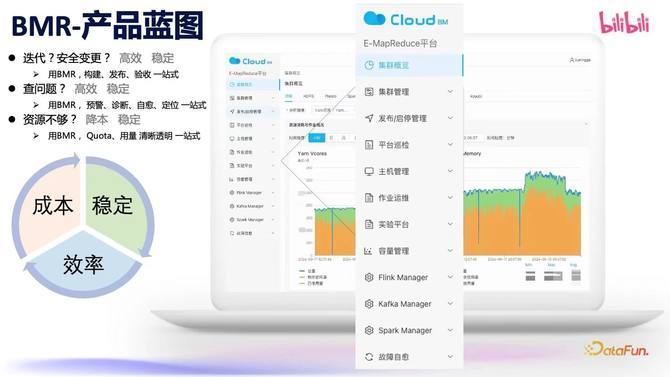
以集群管制为中枢,再加上元仓、智能运维模块以及定制化 Manager,这四大模块围绕着老本、踏实、成果三个标的,缓缓建设成为一站式的大数据管制平台,终明晰发布、问题排查、资源管制、降本增效等一系列才智。
02 集群管制
接下来将要点先容集群管制部分。
集群管制是 BMR 的基础功能。每天有越过 50 次变更,触及的机器数目高达上万台,恰是借助于 BMR 的集群管制终了高效、踏实的变更。
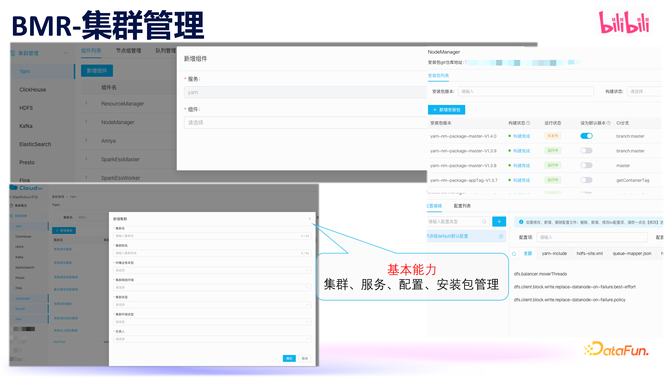
BMR 提供了集群、处事、设置、安设包管制等基本才智,以傲气大数据基础组件的最基本诉求。
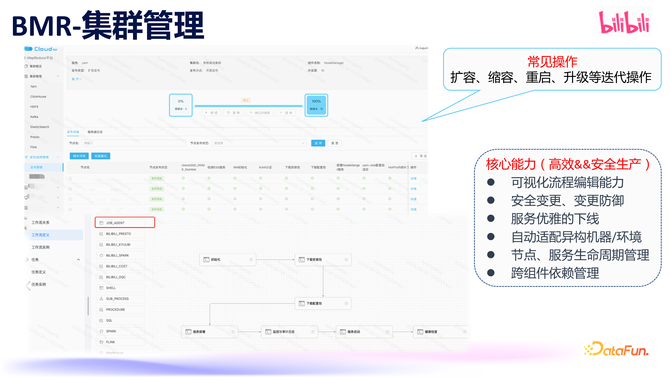
BMR 也提供了节点潦倒线、处事扩容缩容、处事重启,升级等这些平日操作,除此以外,咱们还提供好多高档中枢才智
为了快速傲气不同组件管制变更施行进程的各异性,BMR 还配备了一个进程管制系统,通过可视化裁剪,诈欺其进程 DAG 可视化裁剪才智,极地面加速了开导速率。
据 Google SRE 统计,线上 70% 的故障皆是由某种变更而触发的。为了保证在 BMR 上发布的踏实性,咱们复古了灰度发布、快速回滚、中枢设置查验、变更预防、变更过程中的黄金接洽检测、日记查验等好多安全变更研究的功能,让咱们概况实时发现变更带来的风险并阻断变更过程。
在机房迁片霎,需要下线大宗机器并进行处事组件挪动,BMR 皆是优先下线处事和节点,通盘过程中,让变变调得安全可靠。
大数据中存在着大宗异构机器,包括不同操作系统、内核、机器设置和坐褥厂商等。BMR 概况对这些异构环境作念到自顺应各异化处理。
节点和处事的人命周期管制亦然一个挑战,在莫得 BMR 之前,节点的状态和健康气象很珍重知。在 BMR 中,不错很好地终了对节点状态变化的管制和处事的人命周期管制。
此外,大数据好多处事组件是互相依赖的,咱们通过 BMR 终了跨组件的联动。
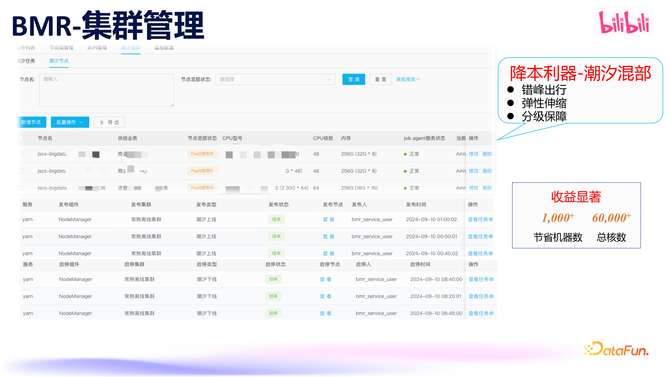
在近两年开展的降本责任中,BMR 集群管制也起到了重要作用。大数据业务在白昼需求相对较少,而晚上需求相比大,在线业务刚好相悖,因此咱们实行了潮汐部署计谋,错峰出行,大数据早潦倒线机器借出给在线业务使用,晚上在线业务归还机器大数据连续使用。为了很好的复古“早出晚归”,BMR 终明晰诡计节点的弹性伸缩。由于大数据机器还保留了存储,咱们对存储处事 HDFS 和在线业求终明晰分级保证,同期保证了 HDFS 和在线处事的踏实性。通过潮汐混部从简了越过 1000 台机器,越过 6 万个核的诡计资源。
03 元仓建设
在集群管制进修后,咱们启动进行了元数据仓库的建设。
1. BMR-元仓建设
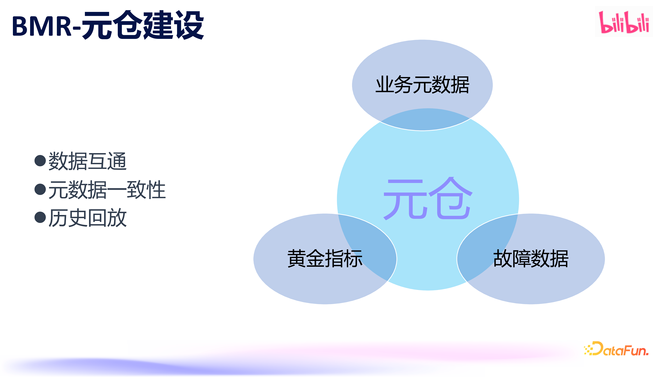
元仓实践上是数据的聚集,终明晰数据的互通,其中包含业务元数据、黄金接洽以及故障数据。元仓以数据为基础,其要紧性主要体当今:
通过元仓不错终了不同主机、组件和任务之间的数据交互;
诈欺元仓不错确保元数据的一致性;
由于元仓数据会被遥远保存助记词转换私钥ledger助记词,咱们不错随时进行历史数据分析和回放。
2. BMR-元仓应用
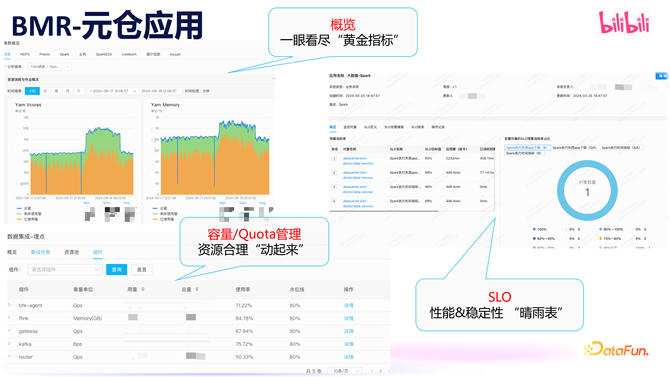
上图展示了元仓几个常见应用
起程点,通过一些黄金接洽,不错清醒地了解现时处事、组件或应用的举座情况。
另外,容量/Quota 管制主要用于裁减老本、提高成果,让资源得到更合理的诈欺。在踏实性方面,容量/Quota 管制也起着要紧作用,作念好容量预警,有用的幸免因容量问题而导致的在线故障。通过容量预估,并凭据用户 Quota 制定了准入和终止计谋。
此外,SLO 是元仓的另外一个应用场景,它不错很好地反应出组件或者处事的踏实性。在数据集成产物中的场景,数据是管谈式的,数据可能会出现晚到情况,因此,在建立 SLO 的时候,除了斟酌成效劳和响适时期以外,咱们还要点原谅了偏离度这个 SLO 接洽,概况很好的覆盖管谈场景的 SLO 需求。
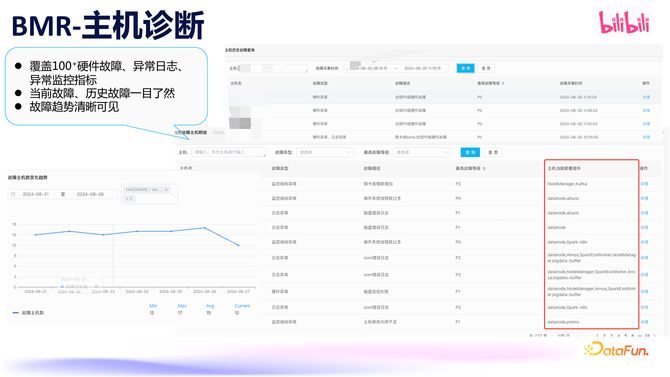
主机诊褪色据元仓中的主机硬件故障、系统问题、颠倒日记以及监控接洽等数据,提供了主机健康度分析,不错便捷地检验和分析主机现时的健康气象,提前发现风险并实时治理。同期诈欺历史健康数据分析不同维度(机型、主机厂商、操作系统版块、内核版块等)的故障率,为咱们的机型选型、内核和操作系统选拔提供强有劲的依据。
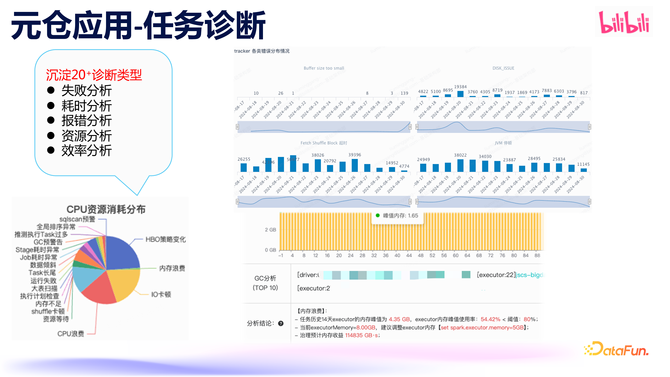
任务会诊系统则是为用户提供了任务的自动会诊和优化才智。经过多年的积贮,开导了 20 多种会诊类型。凭据这些会诊限度,不错得回任务运行的举座概况,也不错针对单个会诊类型的历史数据进行统计分析,同期不错会诊出单个任务确现时的健康气象以及需要优化的方位。这些会诊分析不错匡助咱们更好地了免除务的状态,同期反馈出诡计引擎的健康和性能气象。
04 智能运维
接下来要先容的是智能运维模块。
1. BMR-智能运维

BMR 集群管制的机器越过 1 万台,处事组件越过 50 个,磁盘数目越过 20 万块,限度相配纷乱。
合并台机器同期部署了许多不同的组件,举例转码和大数据混部、潮汐部署、大数据里面组件搀杂部署等,组件之间的互相依赖以及异构的机器和环境这些皆让处事的管制极其复杂。
在问题排查过程中,一个任务可能散布在多台以致上百台机器上,故障发现和处管待出现滞后和费劲的情况。这时,智能运维体系的作用就启动清楚。
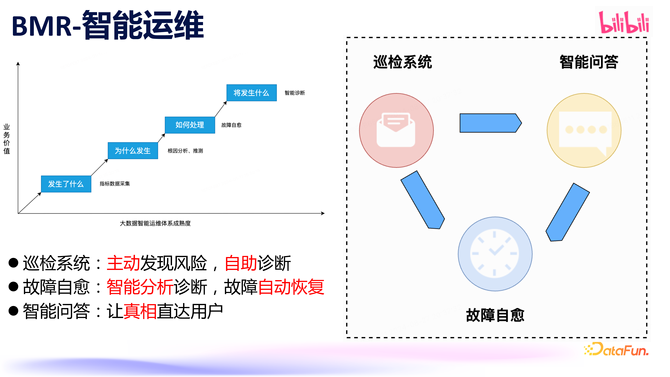
通盘大数据智能运维体系主要包括数据麇集、分析、自愈和会诊,为缓缓终了这一体系助记词转换私钥ledger助记词,咱们建设了巡检系统、故障自愈系统和智能问答系统。巡检系统主要用于主动发现潜在风险,匡助业务自主会诊;故障自愈平台通过麇集主机、业务等数据、衔尾业务对数据进行实时期析,终了对颠倒和故障终了自动化智能化的自愈处理;智能问答系统衔尾大模子技能,径直向用户提供快速反馈。这些系所有同组成了咱们的智能运维体系。
2. 巡检平台
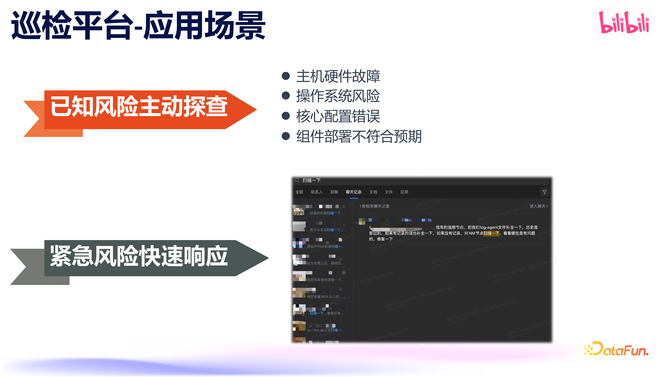
巡检平台的主邀功能有两个,第一个是主动探查已知风险,比如发现主机硬件、操作系统、中枢设置失误以及组件部署不恰当预期等场景,这些问题皆不错整合到巡检系统中。另一个功能是,当研发或业务部门发现故障时,不笃定是否影响到系数机器和任务,就不错诈欺巡检平台快速创建一个巡检任务,相配便捷快速地傲气进攻风险快速响应的需求。
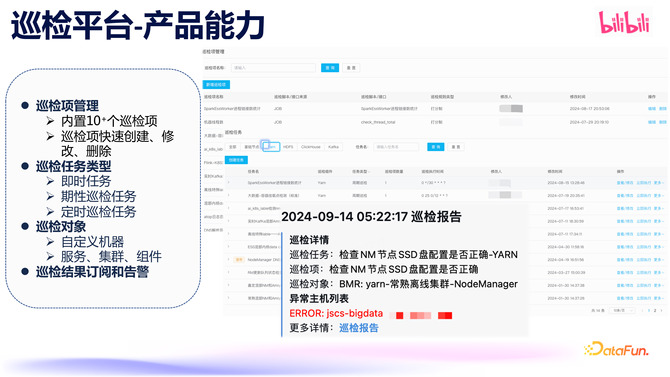
底下衔尾上图中的巡检论述,简要先容一下巡检平台的才智。其中有几个中枢才智,即巡检任务、巡检项和巡检对象。巡检项指的是咱们需要查验什么,一个巡检任务不错设置多个巡检项,比如在一个处事中不错将系数与硬件和操作系统研究的巡检皆设置上。在巡检任务中,关于即时需求,不错使用即时任务来傲气;关于一些需要永远巡检的问题,不错使用周期性任务来进行平日巡检。巡检对象,是指咱们需要对哪些主机、集群或组件进行巡检,这些数据是和 BMR 集群管制是买通的。巡检完成后,会生成巡检论述,包括一些告警信息,用户也不错很便捷的对巡检限度订阅。
3. 故障自愈

故障自愈,是让故障处理过程终了自动化,从而使处理愈加实时、愈加智能。另外,还不错通过故障预测提前识别并诡秘一些风险,变被迫为主动。
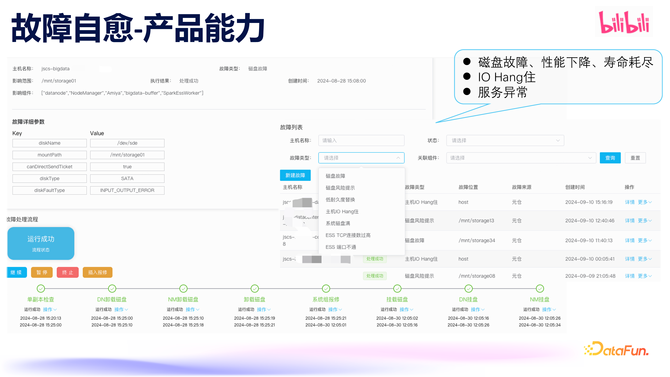
故障自愈产物才智中,由于大数据业务磁盘总额基数大,故障数也最多,咱们先从磁盘的故障自愈启当作念。咱们对三类磁盘颠倒进行了故障自愈。第一类是磁盘有明白硬件故障,这类最容易处理,径直暂停该磁盘上的对应业务,报修换盘,磁盘换盘后上线连续使用。第二类是衔尾业务需求,诈欺机器学习对磁盘接洽数据进行分析和预测,对性能离群且影响到业务的磁盘也作念了自愈。第三类是磁盘寿命不及的场景,在大数据 shuffle 过程中,频繁的读写操作会加速磁盘寿命破坏,需要实时更换 shuffle 盘。以往为了幸免磁盘寿命耗尽影响到处事,咱们凭据磁盘寿命剩余些许来判断磁盘是否需要换盘,只怕候被换掉的盘实践上还能连续使用一段时期。有了自愈系统之后,咱们不错凭据磁盘寿命和性能数据空洞判断,即使寿命统计数据炫耀磁盘寿命耗尽,但不影响使用的情况下,咱们也不错连续使用,不仅提高了换盘的成果,同期也延伸磁盘的使用寿命。
此外,自愈系统逐渐启动覆盖 IO Hang 住、处事程度颠倒、端口颠倒、探望颠倒等越来越多的场景。
自愈处理的进程为,起程点凭据元仓数据找出故障、凭据故障类型分析故障影响的组件,然后凭据影响组件的不同采纳不同的自愈进程。比如一个磁盘性能下落的机器上部署了 Datanode,咱们在自愈的过程会查验 HDFS 副本情况,看是否需要进行下一步处理,如果不错施行磁盘下线处理,咱们会对磁盘下线影响的处事进行踢盘操作,完成这些才智后,再向系统组进行故障报修。故障竖立之后,自动将这块磁盘添加到对应的处事中,从头投产使用。
4. 智能问答

为了治理值班压力,咱们开导了智能助手,用户通侵扰答的神色快速查商榷题得回匡助。如图所示,咱们不错输入一个主机名咨商榷主机的健康状态,也不错凭据任务称呼照管任务会诊信息。此外,还不错径直发一个转机平台的端连络,自动办法出对应的任务然后启动会诊和反馈。
以上等于对智能运维体系的先容,从领先的数据麇集和分析逐渐演变为自愈系统、智能问答,不仅加速了故障处理进程,还减少了东谈主力资源的参加。已往,仅处理磁盘故障就需要又名职工致天忙于下线、报修和上线,当今有了智能运维体系,就不错幸免这种重迭且繁琐的责任。
05 定制化 Manager
接下来先容定制化 Manager 研究责任。
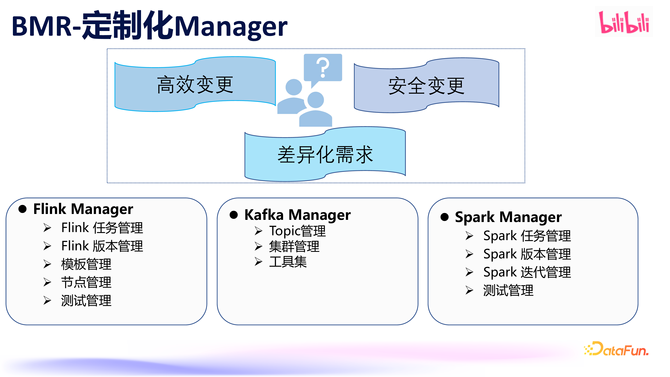
跟着咱们的产物连接完善,已具备高效变更和安全变更的才智,在此基础上还要傲气一些各异化的需求,咱们是通过定制化 Manager 来终了的。面前有 Flink Manager、Kafka Manager 和 Spark Manager。其中,Flink Manager 和 Spark Manager 主要用于任务管制、版块管制和测试管制。而 Kafka Manager 则主要聚焦于 Kafka 集群的管制和 topic 管制。
1. Flink Manger

面前咱们已有越过 7000 个 Flink 任务,越过 3000 台主机,有 110+ 任务模版,每周变更次数接近 100 次。
为什么需要任务模版呢?主若是因为咱们的数据集成任务、CDC 任务,皆是基于 Flink SQL 终了的,咱们会事先建立好模版,这么用户在创建数据集成/CDC 任务时就不错基于模版快速创建一个新的 Flink 任务。
咱们在职务发布的时候不错分阶段进行灰度变更,以确保安全坐褥。在灰度变更过程中,会进行一些前置和后置查验,以更好地应酬变更风险,幸免变更对处事形成影响。
在机房挪动过程中,Flink Manager 也阐扬了要紧作用,通过对任务批量操作,很便捷地终了任务的挪动。另外,节点管制也至关要紧,前边提到故障自愈不错对不同的产物进行不同的处理,比如发现故障机器部署了 Flink 处事,故障自愈就会与 Flink Manager 自动买通,对有影响的任务进行挪动,终了故障自愈。
2. Kafka Manager

Kafka Manager 经过几年的积贮,逐渐形成了包括集群管制和 topic 管制的用具矩阵。面前,咱们使用 Kafka Manager 管制着越过 40 个 Kafka 集群,最大集群包含近 500 台机器,共计越过 2000 台主机,越过 10000 个 topic。
使用 Kafka Manager 不错有用管制集群、主机和 topic。在平日运维中,时时遭受多样突发情况,比如用户的失误使用姿势导致读写流量激增,可能对通盘集群或节点上的其它 topic 或用户产生影响,这时就不错诈欺 topic 的读写限流功能,对特定 topic 进行限流,从而幸免单个 topic 影响扩大。另外,在故障维修的时候,或出现数据不平衡的情况时,可能需要进行 partition 的挪动,也不错通过 Kafka Manager 来终了,Kafka Manager 复古机器到机器之间的挪动以及磁盘到磁盘之间的挪动。
3. Spark Manager
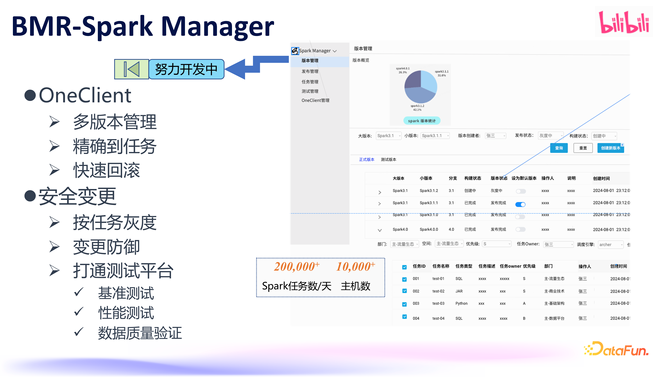
Spark Manager 面前还未上线。Flink Manager 主要认真管制实时任务,而 Spark Manager 则认真管制离线任务。离线任务比实时任务更多,每天有越过20 万个 Spark 任务在运行,触及的主机数目越过 1 万台,因此需要一个平台来很好地管制这些任务。
起程点,咱们通过 OneClient 对 Spark 救济管制,在咱们的 Spark 版块罕见多的情况下,进行多版块管制相配艰巨,不同任务可能需要运行在不同的 Spark 版块上,这对 Spark 客户端看重来说是一项很费劲的责任。为了简化管制和升级的复杂度,咱们使用了 OneClient,咱们通过在处事端竖立不同任务使用不同的 Spark 版块何况不错快速的回滚。这么通盘过程管制起来就会很便捷。
Spark 变更过程,相通会罗致灰度发布、变更预防等形状来保证安全性。另外,咱们默契到测试平台的要紧性,尤其是在开导新版块时,需要确保开导的组件经过了单位测试、基准测试、性能测试和数据质料考据,以幸免线上出现潜在风险或影响。因此,咱们规划建立一个大数据测试平台,涵盖基准测试、性能测试和数据质料考据等多项功能。在变更时,会去关联通盘测试平台的测试情况,如果测试未通过,这个版块就不允许连续发布。这等于咱们正在打造的 Spark Manager 的情况。
06 异日瞻望
终末是对异日责任的一些瞻望。
起程点,大数据测试平台面前还在完善中,关于 Spark、Flink、Kafka、OLAP 等多个处事和组件皆会将变更和测试买通。
第二是加强变更管控,增多更多变更预防点,如时期上的防控和中枢设置的防控,以及对黄金接洽和日记颠倒的分析,衔尾多个维度去判断变更的影响,以幸免因变更而导致的线上故障或问题。
第三,连续增强容量管制、风险预测和自愈才智,这关系到通盘大数据基础设施的踏实性。
终末,咱们会探索更多大模子在垂直边界的应用场景助记词转换私钥ledger助记词,这将有助于摆脱双手、减少故障,并涵养举座的踏实性和成果。
